tdを使って集計しようと思ったのですが、Long型をソートしたら文字列型としてソートされてしまい、しばらく悩んだ時のメモです。
データの登録
まず、1行1JSON形式のファイルを用意して、bulk_importをしました。 手順としては以下のような感じです。
td table:create db1 video td import:create s1 db1 video td import:prepare video.json --format json --time-value 1385028000 -o ./v/ td import:upload s1 ./v/* td import:show s1 td import:freeze s1 td import:perform s1 -w td import:list td import:error_records s1 td import:commit s1 # wait commiting -> commited td import:delete s1
これで 3590406 行のデータを投入しました。
スキーマの設定
次に、Webの画面からSchemaの設定を明示的に行いました。
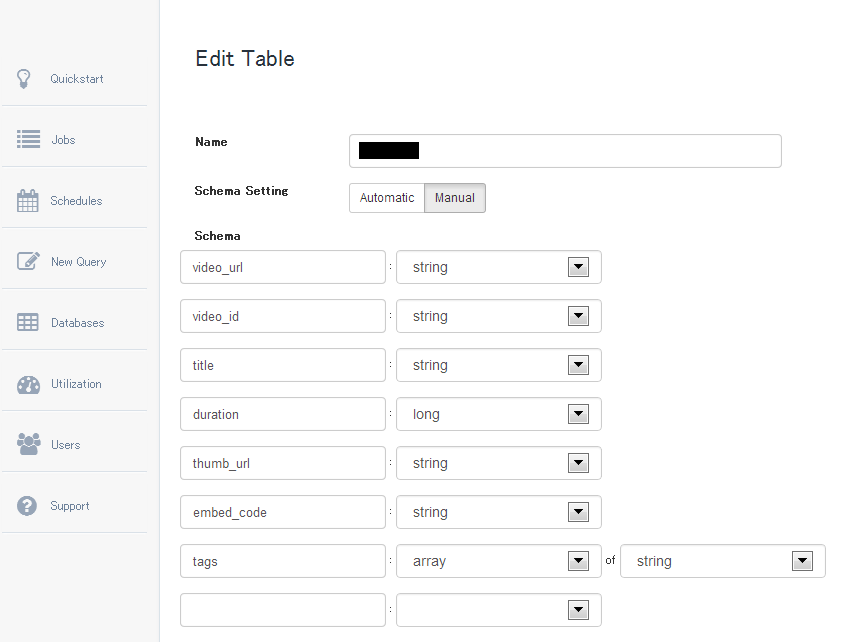
ちゃんと設定されているか、コマンドラインからも確認。
td table:show db1 video
Name : db1.video
Type : log
Count : 3590406
Schema : (
video_url:string
video_id:string
title:string
duration:long
thumb_url:string
embed_code:string
tags:array<string>
)
durationがきちんと整数型になっているかを確認するために、以下のコマンドで確認。(実行結果は省略します)
td table:tail db1 video
いざ、クエリ発行
そんでもってWebからクエリを発行。
select * from video order by v['duration'] desc limit 10000
すると、結果が以下のようになり、「あれ!?」っと思ったわけです。文字列としてソートされている・・。
999 999 999 ... 9981 ...
というわけでサポートに問い合わせてみたところ、以下のことがわかりました。
わかったこと
v という変数は map<string, string> 型である。つまり、v['duration'] という式はstring型を返します。なので order by v['duration'] とやっても文字列としてソートされるわけです。
解決策として2つ教えて貰いました。
1. 明示的にスキーマの設定をしているため、v['duration']ではなく、 duration で参照可能。つまり、以下の用に記述すれば整数型として扱われます。
select * from video order by duration desc limit 10000
2. HiveのUDFにCastがあるので、以下のようにINT型にCastする。
select * from video order by cast(v['duration'] as INT) desc limit 10000
まとめ
v は map<string, string>であるという事を忘れると、こういう事態を招きます。
普段TD使っている人にとってはなんてこと無いのかもしれませんが、しばらく悩みました。
夜中の1時(JST)にTDのサポートにメール出したら3時間で返信が来た。(アリガトウ Jeffさん)
本当はDB名がlibidoでテーブル名がxvideosだったので、問い合わせるのがすげー恥ずかしかった(´・ω・`)
おまけ
td table:partial_delete でデータを消す場合、 from, toを3600秒単位じゃないとエラーが出るのは、S3上では1時間単位でディレクトリ(と言って良いのかわからないけど)を切っているからなんですね。 こんな感じのログが出ているので。
13/11/20 11:48:04 INFO c3p0.C3P0Registry: Initializing c3p0-0.9.1.2 [built 21-May-2007 15:04:56; debug? true; trace: 10] 13/11/20 11:48:04 INFO partialdelete.PartialDeleteWorker: Delete records that have 'time' value between '0' to '1385046000' 13/11/20 11:48:04 INFO storage.S3StorageBackend: listing s3 files from ***/db1/video_20131120_095234_6ee49185/1970/01/01/00/ to ***/db1/video_20131120_095234_6ee49185/2013/11/21/15/
ただ、partial_deleteしても表示上のテーブルの合計レコード数は減らないので、齟齬がでる事になり注意が必要です。一度データを削除して、もう1回インポートしてたら、以下のように倍になります。
まぁHiveで普通にcount(*)すれば正常な結果が帰ってくるのでクエリで集計する分には問題はないのですが。
+----------+------------+------+-----------+--------+ | Database | Table | Type | Count | Size | +----------+------------+------+-----------+--------+ | db1 | video | log | 7,180,812 | 0.3 GB | +----------+------------+------+-----------+--------+