なんかタイトルがラノベっぽい。
Fluentd Casual Talks #2 に参加してきたので、その感想でも。
-- 感想 --
JRの駅からヒカリエに行く方法がわからず、20分ほどうろうろして最終的に駅員さんに聞きました。くやしくなんかないもん。(震え声)
just_do_neet さんの運用の話は、とても良かったです。とりあえず入れてみて、それっぽく動いている。ハッピー。 というわけでもなく、きちんと検証したんだなーという感じが特に。駆け足だったので、ちゃんと追えていないけど・・(´・ω・`)
そしてangostura11さんがStreamに対してクエリを発行できるものを発表されていて、それってかなり便利なんじゃ。。でもJavaかぁーとか思ったり、Spring_MTさんの話でFluentdがテスト用のドライバを用意しているという事を知り、じゃぁテスト書くの楽なのかもとか思って、会場の後ろの方でpluginをこそこそと書き始めていました。
他の発表者の方も、短い時間でテンポ良くしゃべっていて、一部の内容は理解できなかったけど、タメになったなぁという感じです。
それはそうと、oza_x86さんのデスクトップ(?)にHADOOPのパッチが沢山置いてあったのが一番気になりました(;゜ロ゜)
-- 感想終わり --
-- 次は Fluentd について思っていること --
もうあちこちで言われているので、わざわざ書く必要もないかもですが、個人的にFluentdの良いところというのは、再送処理を現実的な範囲でそれなりに担保してくれるという事と、in_tailプラグインの存在だと思っています。
Webの例なんかはあちこちに出ているので、他の・・例えば400台くらいのゲームサーバがあったとして(昔CEDECで発表されていたの、これくらいでしたよね)、それのログはローカルDISKに書き込むか、専用のログサーバに転送するか、もしくはその両方を行うとかやると思います。ここまでかっちりと作ってあるものなら、まぁ別にそれなりに動きますが、時としてローカルDiskにのみログを出力しているものがあります。
ちなみに、(自分が知っている範囲で言うと)オンラインゲーム(ソーシャルゲームじゃないよ)のログというのは、ユーザー比率的にWebのログよりも圧倒的に多く、ちょっと追加しようものなら、ものすごい勢いでDiskを食いつぶしていきます。
話はそれましたが、まぁとにかくローカルDiskに書き込むケースが多いわけです。で、これを何かしらの方法で集約するか、もしくはその各ホスト上で直接分散検索をしたりするわけです。これで困る点はホストが壊れて代替機に振り替えた場合、そのホストにあるログが・・・ という問題があるわけです。集約するにしても、バッチ処理的に吸い上げるとスパイクな負荷がかかります。まぁこれもあちこちで言われている話なので言うまでもないですね。
で、in_tailの何がすばらしいかというと、既に作ってあるアプリケーションに対して何も変更を行うことなく、外部プロセスでStreamで他所の場所に集約できるという点です。 これ、かなり嬉しかったです。昨年のCEDECで国民的ゲームのデータベースの発表をした人も、in_tail イイね!と話した記憶があります。
そんなわけで、 in_tail を標準のpluginで入れているのは実は凄く素晴らしい事なんだと思っているわけです。
(当たり前すぎるのか言及している人を見かけない・・(´・ω・`))
-- Pluginを作ってみた話 --
話を聞いて、まぁ私もPluginを書いてみるかと思うわけですが、実際に書いてみると、コピペをしない場合は最終的にソースを見る羽目になるわけです。
例えば、テストを書くにしてもドキュメントを見ると、out_fileのテストを参考にしなって書いてあるし、何を継承するかとか、親クラスは何のパラメータを持っているのかとか、ソースを見ないと分からない(分かりづらい)わけで。こんなパラメータ合ったんだとか (例えば num_threads なんかは一部のTwitterと一部のBlogにちょろっと出てくるくらいです)、新しい発見があって、fluentdに限って言えば、pluginを1回書いた方が理解が深まるなと思いました。
その肝心のpluginの作り方ですが、pluginを○時間で書いたとかいう話をPlugin製作者が言ってますが、実際そーいうレベルの時間で書くことができました。outputプラグインに関しては、驚くほど抽象化されているので、やりたい事だけをペイッと書くだけです。めんどくさい処理はMixinで提供されいるので、楽ちんです。ただ、存在を見つけるのに時間がかかりました・・(´・ω・`) このドキュメントに載っていないので、複数のPluginのソースを参考にして、fluentdやpluginのソースを検索しまくりでした。
テストもドライバが用意されているので、TDDで書くことができます。
-- fluent-plugin-arango について --
そんなわけで、ArangoDBに書き込むためのpluginを書いてみました。ソースはこちらに、Gemはこちらにあります。 ArangoDBは最新版ではbulk_importを持っているのですが、rubyのclientであるashikawa-coreがまだサポートしていないので、1件ずつ書いています。
(そういえば、Collection勝手に作るから、wait_syncのパラメータが必要かも)
使い方はこんな感じです。
<match access.**> type arango collection ut_col scheme http host localhost port 8529 </match>
BufferedOutputを継承し、SetTimeKeyMixin, SetTagKeyMixinをincludeしているので、それらのパラメータも指定する事ができます。 詳しくはREADMEに記載しています。
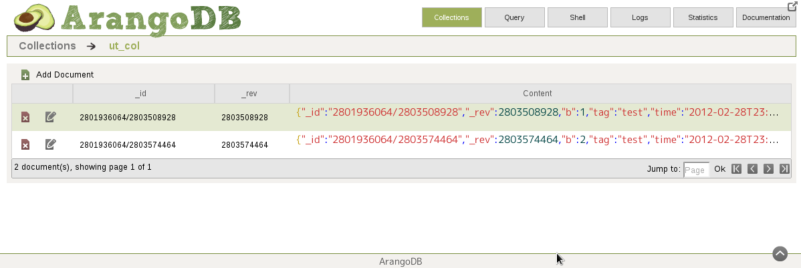
実際にArangoDBのWebUIから確認をすると、データが入っています。
何かまずい点をみつけたら、ご指摘いただけると嬉しいです。